Random forests are an ensemble learning method for classification, regression and other tasks, that operate by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean prediction (regression) of the individual trees. Random decision forests correct for decision trees’ habit of overfitting to their training set.
Random Forest builds many trees using a subset of the available input variables and their values, it inherently contains some underlying decision trees that omit the noise generating variable/feature(s). In the end, when it is time to generate a prediction a vote among all the underlying trees takes place and the majority prediction value wins.
Ensembles are a divide-and-conquer approach used to improve performance. The main principle behind ensemble methods is that a group of “weak learners” can come together to form a “strong learner”. The figure below provides an example. Each classifier, individually, is a “weak learner,” while all the classifiers taken together are a “strong learner”. The data to be modeled are the blue circles. We assume that they represent some underlying function plus noise. Each individual learner is shown as a gray curve. Each gray curve (a weak learner) is a fair approximation to the underlying data. The red curve (the ensemble “strong learner”) can be seen to be a much better approximation to the underlying data.
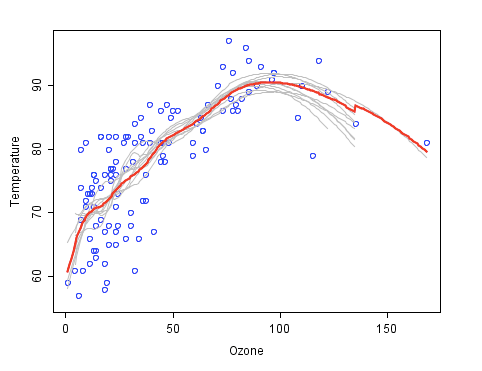
Bagging vs. Boosting
A too complex model (unpruned decision trees) have high variance but low bias whereas a too simple model (Weak learners like decision stumps) have high bias but low variance. To minimize these two types of errors two different approaches are required namely bagging (complex models/high variance) and boosting (simple models/high bias).
- Bagging (stands for Bootstrap Aggregation) is the way decrease the variance of your prediction by generating additional data for training from your original dataset using combinations with repetitions to produce multisets of the same cardinality/size as your original data. By increasing the size of your training set you can’t improve the model predictive force, but just decrease the variance, narrowly tuning the prediction to expected outcome. Random Forest is a typical example of bagging.
- Boosting is a two-step approach, where one first uses subsets of the original data to produce a series of averagely performing models and then “boosts” their performance by combining them together using a particular cost function (=majority vote). Unlike bagging, in the classical boosting the subset creation is not random and depends upon the performance of the previous models: every new subsets contains the elements that were (likely to be) misclassified by previous models. Adaboost is a typical example of boosting.
Decision Trees and Random Forests
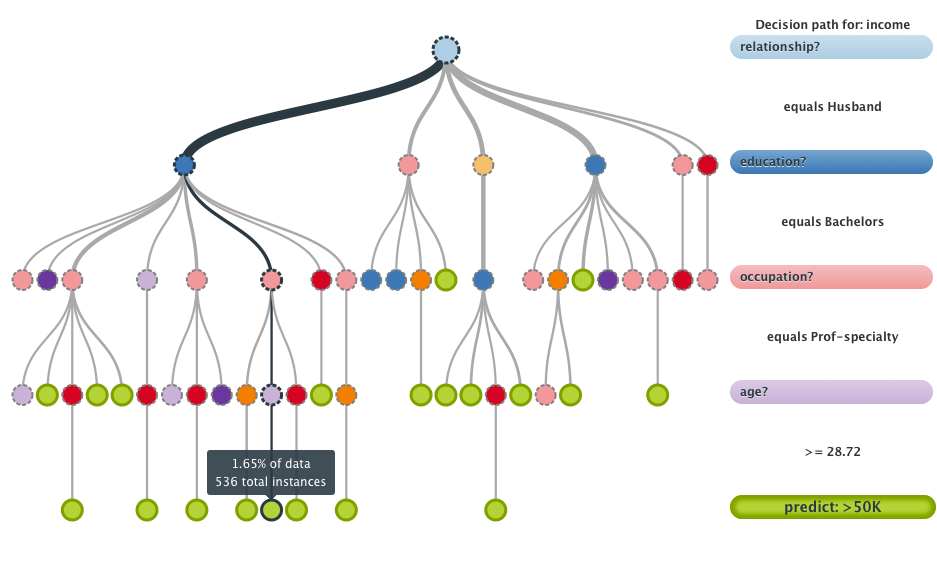
The random forest starts with a standard machine learning technique called a “decision tree” which, in ensemble terms, corresponds to our weak learner. In a decision tree, an input is entered at the top and as it traverses down the tree the data gets bucketed into smaller and smaller sets. For details see here, from which the figure below is taken.
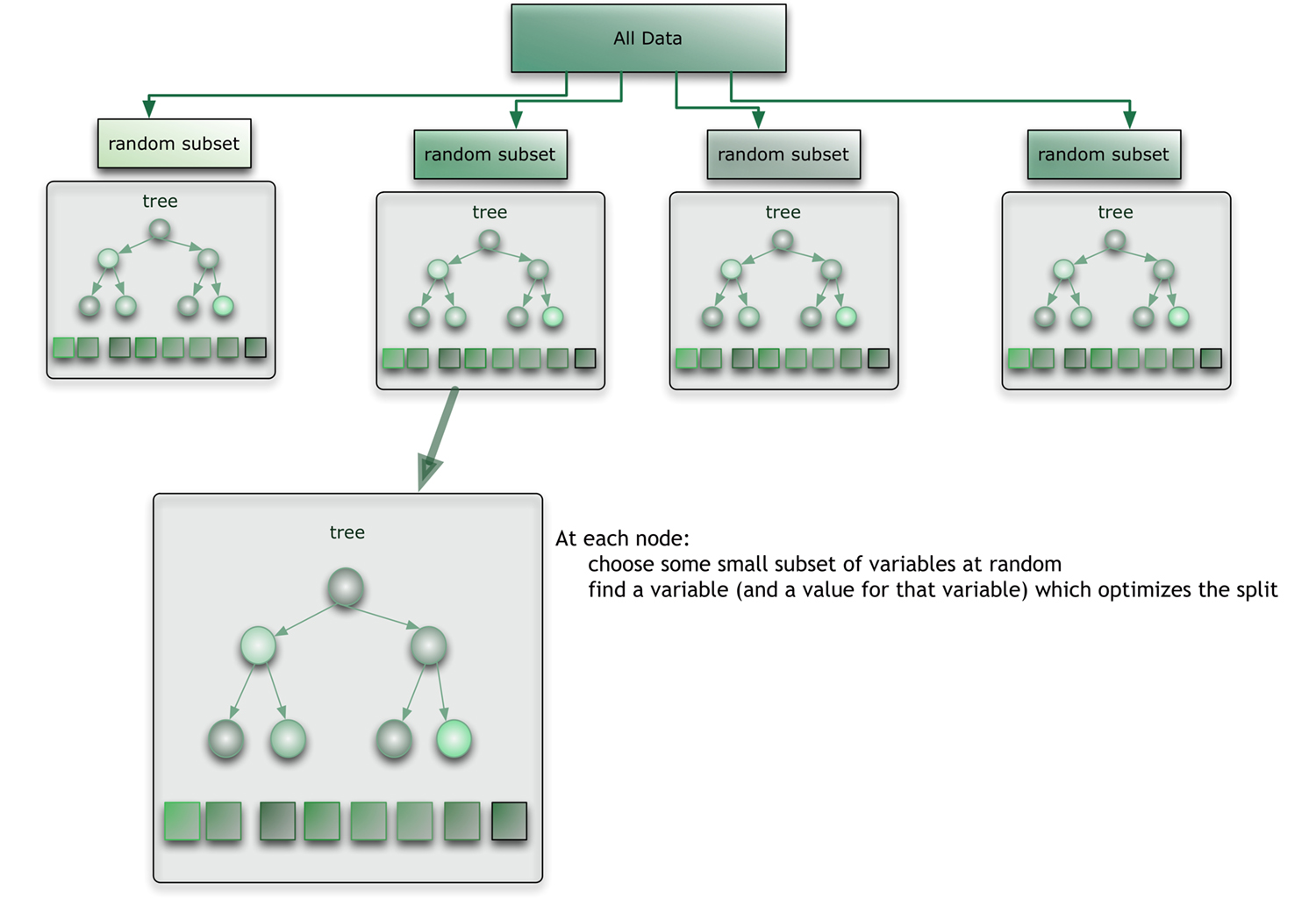
The random forest (see figure below) takes this notion to the next level by combining decision trees with the notion of an ensemble. Thus, in ensemble terms, the trees are weak learners and the random forest is a strong learner.
The Disqus comment system is loading ...
If the message does not appear, please check your Disqus configuration.