Consistent Hash Ring
Consistent hashing is a special kind of hashing such that when a hash table is resized and consistent hashing is used, only K/n keys need to be remapped on average, where K is the number of keys, and n is the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped.
Consistent hashing achieves the same goals as Rendezvous hashing (also called HRW Hashing). The two techniques use different algorithms and were devised independently and contemporaneously.
Problem with Distributed Cache
The need for consistent hashing arose from limitations experienced while running collections of caching machines - web caches, for example. If you have a collection of n cache machines then a common way of load balancing across them is to put object o in cache machine number hash(o) mod n. This works well until you add or remove cache machines (for whatever reason), for then n changes and every object is hashed to a new location. This can be catastrophic, since the originating content servers are swamped with requests from the cache machines. It’s as if the cache had suddenly disappeared. This is exactly the problem consistent hashing is designed to avoid.
Consistent Hashing
Consistent hashing was first described in the 1997 paper Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web by David Karger et al. It is used in distributed storage systems like Amazon Dynamo, memcached, Project Voldemort and Riak.
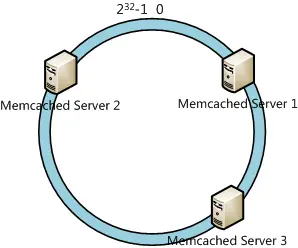
It’s assumed that the range of hash values is $[0, 2^{32}-1]$, and we calculate the hash value of each server (using its IP address or hostname), as shown in the figure below.
Suppose we have 4 data objects and we calculate the hash value of each one and place them on the hash ring, as the figure below shows:
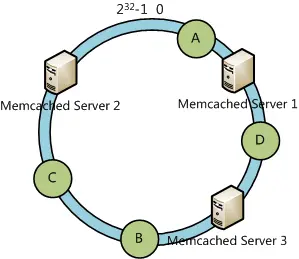
According to the consistent hash algorithm, the data object A will be located in Server 1, the data object D will be located in Server 3, and the data objects B and C will be located in Server 2.
Error Tolerance and Scalability
In this section, we are going to talk about the error tolerance and scalability in a consistent hashing algorithm.
Suppose that Server 3 is down, as the figure shows below:
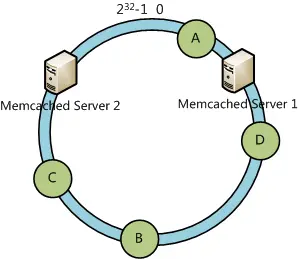
We’ll find that the data object A, B, and C are still available. At this time, the data object D will be located on Server 2.
In the general hashing algorithm, all locations of data objects will be changed. However, only partial data objects will be relocated in a consistent hashing algorithm.
What if we add a server to the hash ring?
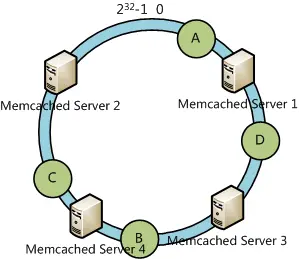
We’ll find that only the data object B is relocated to Server 4.
Virtual Nodes
So far the algorithm seems to work well. However, the size of the intervals assigned to each cache is pretty hit-and-miss. Since server positions are essentially random, we can end up with a very non-uniform distribution of objects between caches. In the figure below, for example, Server 1 stores most of the data objects, which decreases the performance of the hash ring.
The solution is to introduce “virtual nodes”, which are replicas of cache points placed around the circle. Whenever we add a cache, we create a number of points on the ring for it by appending serial numbers to its IP address or hostname. For the case above, we create 3 virtual nodes for each server (Memcached Server 1#1, Memcached Server 1#2, Memcached Server 1#3, and so on), giving us 6 virtual nodes in total.
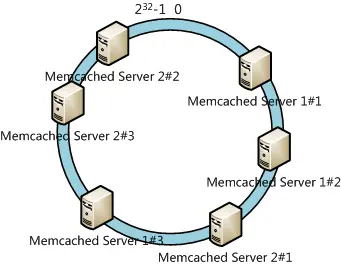
Any data object that lands on Memcached Server 1#1, Memcached Server 1#2, or Memcached Server 1#3 is actually stored on Memcached Server 1. Spreading each physical server across many points on the ring evens out the distribution of objects between caches.
Usage
So how can you use consistent hashing? You are most likely to meet it in a library, rather than having to code it yourself. For example, as mentioned above, Memcached, a distributed memory object caching system, now has clients that support consistent hashing. Last.fm’s ketama by Richard Jones was the first, and there is now a Java implementation by Dustin Sallings. It is interesting to note that only the client needs to implement the consistent hashing algorithm; the Memcached server itself is unchanged. Other systems that employ consistent hashing include Chord, a distributed hash table, and Amazon’s Dynamo, a key-value store.
The Disqus comment system is loading ...
If the message does not appear, please check your Disqus configuration.