HashMap Internal Implementation Analysis in Java
HashMap is one of the most common topics in Java interviews, and “How does HashMap work?” has a deceptively simple one-line answer: “On the principle of hashing.” To say anything more, you need to know how hashing works and how HashMap applies it internally.
This post assumes you already know the basics of using a HashMap; if not, start with the official Java docs. The walkthrough below uses the pre-Java-8 source as its baseline; wherever Java 8+ changed the implementation, an inline Note flags it.
What is Hashing
Hashing in its simplest form is a way to assign a unique code for any variable/object after applying any formula/algorithm to its properties. A true Hashing function must follow this rule:
Hash function should return the same hash code each and every time, when function is applied on same or equal objects. In other words, two equal objects must produce same hash code consistently.
Note: All objects in java inherit a default implementation of hashCode() function defined in Object class. This function produces a hash code by typically converting the internal address of the object into an integer, thus producing different hash codes for all different objects.
About Entry Class
A map, by definition, is “an object that maps keys to values”. So there must be some mechanism in HashMap to store these key-value pairs. It does this through an inner class Entry, which looks like this:
static class Entry implements Map.Entry
{
final K key;
V value;
Entry next;
final int hash;
...//More code goes here
}
Surely Entry class has key and value mapping stored as attributes. Key has been marked as final and two more fields are there: next and hash. We will try to understand the need of these fields as we go forward.
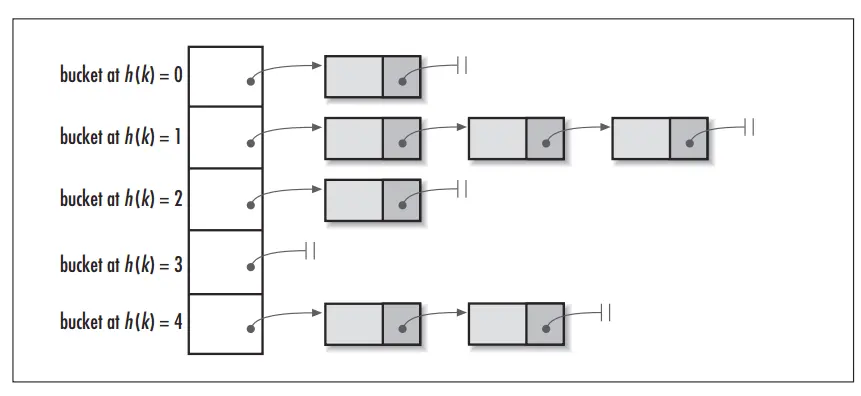
What put() method actually does
Before going into put() method’s implementation, it is very important to learn that instances of the Entry class are stored in an array. HashMap class defines this variable as:
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
Now look at the code implementation of put() method:
/**
* Associates the specified value with the specified key in this map. If the
* map previously contained a mapping for the key, the old value is
* replaced.
*
* @param key
* key with which the specified value is to be associated
* @param value
* value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or <tt>null</tt>
* if there was no mapping for <tt>key</tt>. (A <tt>null</tt> return
* can also indicate that the map previously associated
* <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
Let’s note down the steps one by one:
- First of all, the key object is checked for null. If the key is null, the value is stored in table[0] position. Because the hash code for null is always 0.
- Then in the next step, a hash value is calculated using the key’s hash code by calling its hashCode() method. This hash value is used to calculate the index in an array for storing the Entry object. JDK designers well assumed that there might be some poorly written hashCode() functions that can return very high or low hash code values. To solve this issue, they introduced another hash() function, and passed the object’s hash code to this hash() function to bring a hash value in the range of array index size.
- Now indexFor(hash, table.length) function is called to calculate the exact index position for storing the Entry object.
- Now the interesting part: since two unequal objects can have the same hash code, how are two different objects stored at the same array location (called a bucket)?
The answer is a LinkedList. Recall that the Entry class has a “next” attribute, which always points to the next object in the chain, exactly the behavior of a LinkedList.
Note (Java 8+): The two-step hash(key.hashCode()) and indexFor(hash, table.length) shown here are the pre-Java-8 design. Java 8 simplified the hash spreading to (h = key.hashCode()) ^ (h >>> 16), XOR-ing the high 16 bits into the low bits so that the (n - 1) & hash index calculation still benefits from the upper bits. The standalone indexFor() method was removed and (n - 1) & hash is now inlined directly into put()/get().
So, in case of collision, Entry objects are stored in LinkedList form. When an Entry object needs to be stored at a particular index, HashMap checks whether there is already an entry there. If not, the Entry object is stored in this location.
If there is already an object sitting on the calculated index, its next attribute is checked. If it is null, the current Entry object becomes the next node in the LinkedList. If the next variable is not null, the procedure is followed until the next is evaluated as null.
Note (Java 8+): The description above reflects the pre-Java-8 implementation, where every bucket is a plain linked list. Since Java 8, once a single bucket accumulates more than 8 nodes (TREEIFY_THRESHOLD) and the table size is at least 64, that bucket is converted into a balanced red-black tree, improving the worst-case lookup within a bucket from O(n) to O(log n). The inner class was also renamed from Entry to Node (and TreeNode for treeified bins). If the bucket later shrinks below 6 nodes (UNTREEIFY_THRESHOLD) during a resize, it reverts to a linked list.
What if we add another value object with the same key as entered before. Logically, it should replace the old value. How it is done? Well, after determining the index position of the Entry object, while iterating over LinkedList on the calculated index, HashMap calls the equals method on the key object for each Entry object. All these Entry objects in LinkedList will have a similar hash code but equals() method will test for true equality. If key.equals(k) will be true then both keys are treated as the same key object. This will cause the replacing of the value object inside the Entry object only.
In this way, HashMap ensures the uniqueness of keys.
How get() method works internally
Now we have got the idea, of how key-value pairs are stored in HashMap. The next big question is: what happens when an object is passed in the get() method of HashMap? How the value object is determined?
The answer we already should know is that the way key uniqueness is determined in the put() method, the same logic is applied in get() method also. The moment HashMap identifies an exact match for the key object passed as an argument, it simply returns the value object stored in the current Entry object.
If no match is found, the get() method returns null.
Let’s have a look at the code:
/**
* Returns the value to which the specified key is mapped, or {@code null}
* if this map contains no mapping for the key.
*
* <p>
* More formally, if this map contains a mapping from a key {@code k} to a
* value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* </p><p>
* A return value of {@code null} does not <i>necessarily</i> indicate that
* the map contains no mapping for the key; it's also possible that the map
* explicitly maps the key to {@code null}. The {@link #containsKey
* containsKey} operation may be used to distinguish these two cases.
*
* @see #put(Object, Object)
*/
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
Above code is same as put() method till if (e.hash == hash && ((k = e.key) == key || key.equals(k))), after this simply value object is returned.
Load Factor and Resizing
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
It says the default size of an array is 16 (always a power of 2, we will understand soon why it is always a power of 2 going further) and load factor means whenever the size of the HashMap reaches 75% of its current size, i.e, 12, it will double its size by recomputing the hash codes of existing data structure elements.
Hence to avoid rehashing the data structure as elements grow it is the best practice to explicitly give the size of the HashMap while creating it.
Do you foresee any problem with this resizing of hashmap in java? Since java is multi-threaded it is very possible that more than one thread might be using the same hashmap and then they both realize the need for re-sizing the hashmap at the same time which leads to a race condition.
What is a race condition with respect to hashmaps? When two or more threads see the need for resizing the same hashmap, they might end up adding the elements of the old bucket to the new bucket simultaneously and hence might lead to infinite loops. FYI, in case of collision, i.e, when there are different keys with the same hashcode, internally we use a single linked list to store the elements. And we store every new element at the head of the linked list to avoid tail traversing and hence at the time of resizing the entire sequence of objects in the linked list gets reversed, during which there are chances of infinite loops.
Note (Java 8+): This infinite-loop scenario is specific to the pre-Java-8 resize logic. Java 8 rewrote resize() to split each bucket into a “low” and “high” list while preserving the original insertion order (instead of reversing it via head insertion), which eliminates the cyclic-linked-list problem. HashMap is still not thread-safe; however, concurrent writes can lose updates or corrupt state, so use ConcurrentHashMap for multi-threaded access.
HashTable and ConcurrentHashMap
This is another question which is getting popular due to the increasing popularity of ConcurrentHashMap. Since we know Hashtable is synchronized but ConcurrentHashMap provides better concurrency by only locking the portion of the map determined by concurrency level. ConcurrentHashMap was introduced as an alternative to HashTable and can be used in place of it, but HashTable provides stronger thread safety than ConcurrentHashMap.
ConcurrentHashMap does not allow null keys or null values while HashMap allows null keys.
The Disqus comment system is loading ...
If the message does not appear, please check your Disqus configuration.