Process
What’s Process?
In computing, a process is an instance of a computer program that is being executed. It contains the program code and its current activity. Depending on the operating system (OS), a process may be made up of multiple threads of execution that execute instructions concurrently.
Process states
An operating system kernel that allows multi-tasking needs processes to have certain states. Names for these states are not standardized, but they have similar functionality.
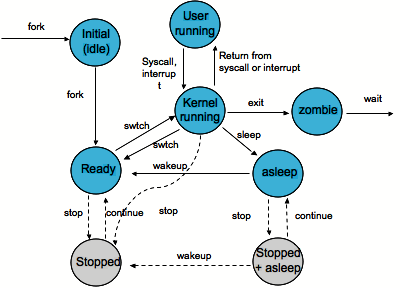
Orphan Process and Zombie Process
Orphan process
An orphan process is a computer process whose parent process has finished or terminated, though it remains running itself.
In a Unix-like operating system, any orphaned process will be immediately adopted by the special init system process. This operation is called re-parenting and occurs automatically. Even though technically the process has the “init” process as its parent, it is still called an orphan process since the process that originally created it no longer exists.
A process can be orphaned unintentionally, such as when the parent process terminates or crashes. The process group mechanism in most Unix-like operation systems can be used to help protect against accidental orphaning, where in coordination with the user’s shell will try to terminate all the child processes with the SIGHUP process signal, rather than letting them continue to run as orphans.
Zombie Process
On Unix and Unix-like computer operating systems, a zombie process or defunct process is a process that has completed execution (via the exit system call) but still has an entry in the process table: it is a process in the “Terminated state”. This occurs for child processes, where the entry is still needed to allow the parent process to read its child’s exit status: once the exit status is read via the wait system call, the zombie’s entry is removed from the process table and it is said to be “reaped”. A child process always first becomes a zombie before being removed from the resource table. In most cases, under normal system operation zombies are immediately waited on by their parent and then reaped by the system – processes that stay zombies for a long time are generally an error and cause a resource leak.
The term zombie process derives from the common definition of zombie — an undead person. In the term’s metaphor, the child process has “died” but has not yet been “reaped”. Also, unlike normal processes, the kill command has no effect on a zombie process.
Inter-Process Communication(IPC)
Interprocess communication (IPC) is a set of programming interfaces that allow a programmer to coordinate activities among different program processes that can run concurrently in an operating system. This allows a program to handle many user requests at the same time. Since even a single user request may result in multiple processes running in the operating system on the user’s behalf, the processes need to communicate with each other. The IPC interfaces make this possible. Each IPC method has its own advantages and limitations so it is not unusual for a single program to use all of the IPC methods.
IPC methods include pipes and named pipes; message queueing; semaphores; shared memory; and sockets.
Thread
What’s Thread?
In computer science, a thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler (typically as part of an operating system). The implementation of threads and processes differs from one operating system to another, but in most cases, a thread is a component of a process. Multiple threads can exist within the same process and share resources such as memory. In particular, the threads of a process share the latter’s instructions (its code) and its context (the values that its variables reference at any given moment).
Multithreading
Multithreading is mainly found in multitasking operating systems. Multithreading is a widespread programming and execution model that allows multiple threads to exist within the context of a single process. These threads share the process’s resources but are able to execute independently. The threaded programming model provides developers with a useful abstraction of concurrent execution. Multithreading can also be applied to a single process to enable parallel execution on a multiprocessing system.
On a single processor, multithreading is generally implemented by time-division multiplexing (as in multitasking): the processor (CPU) switches between different hardware threads. This context switching generally happens frequently enough that the user perceives the threads or tasks as running at the same time. On a multiprocessor or multi-core system, threads can be truly concurrent, with every processor or core executing a separate thread simultaneously. The operating system uses hardware threads to implement multi-processing. Hardware threads are different from the software threads mentioned earlier. Software threads are a pure software construct. The CPU has no notion of software threads and is unaware of their existence.
Drawbacks of Thread
- Synchronization: Since threads share the same address space, the programmer must be careful to avoid race conditions and other non-intuitive behaviors. In order for data to be correctly manipulated, threads will often need to rendezvous in time in order to process the data in the correct order. Threads may also require mutually exclusive operations (often implemented using semaphores) in order to prevent common data from being simultaneously modified or read while in the process of being modified. Careless use of such primitives can lead to deadlocks.
- Thread crashes Process: An illegal operation performed by a thread crashes the entire process and so, one misbehaving thread can disrupt the processing of all the other threads in the application.
User-level Thread and Kernel-level Thread
There are two distinct models of thread controls, and they are user-level threads and kernel-level threads. The thread function library to implement user-level threads usually runs on top of the system in user mode. Thus, these threads within a process are invisible to the operating system. User-level threads have extremely low overhead and can achieve high performance in computation. However, using the blocking system calls like read(), the entire process would block. Also, the scheduling control by the thread runtime system may cause some threads to gain exclusive access to the CPU and prevent other threads from obtaining the CPU. Finally, access to multiple processors is not guaranteed since the operating system is not aware of the existence of these types of threads.
On the other hand, kernel-level threads will guarantee multiple processor access but the computing performance is lower than user-level threads due to the load on the system. The synchronization and sharing of resources among threads are still less expensive than a multiple-process model, but more expensive than user-level threads. The thread function library available today is often implemented as a hybrid model, as having advantages from both user-level and kernel-level threads. The design consideration of thread packages today consists of how to minimize the system overhead while providing access to multiple processors.
How threads differ from processes
- processes are typically independent, while threads exist as subsets of a process
- processes carry considerably more state information than threads, whereas multiple threads within a process share process state as well as memory and other resources
- processes have separate address spaces, whereas threads share their address space
- processes interact only through system-provided inter-process communication mechanisms
- context switching between threads in the same process is typically faster than context switching between processes.
Reference
- http://en.wikipedia.org/wiki/Process_(computing)
- http://en.wikipedia.org/wiki/Orphan_process
- http://en.wikipedia.org/wiki/Zombie_process
- http://en.wikipedia.org/wiki/Inter-process_communication
- http://en.wikipedia.org/wiki/Thread_(computing)
- http://wwwold.ece.utep.edu/research/webfuzzy/docs/kk-thesis/kk-thesis-html/node35.html
The Disqus comment system is loading ...
If the message does not appear, please check your Disqus configuration.