What’s HTTP?
HTTP stands for Hypertext Transfer Protocol. It’s the network protocol used to deliver virtually all files and other data (collectively called resources) on the World Wide Web, whether they’re HTML files, image files, query results, or anything else. Usually, HTTP takes place through TCP/IP sockets (and this tutorial ignores other possibilities).
A browser is an HTTP client because it sends requests to an HTTP server (Web server), which then sends responses back to the client. The standard (and default) port for HTTP servers to listen on is 80, though they can use any port.
Although I’ll mention some details related to headers, it’s best to instead consult the RFC (RFC 2616) for in-depth coverage. I will be pointing to specific parts of the RFC throughout the article.
HTTP Basics
HTTP allows for communication between a variety of hosts and clients, and supports a mixture of network configurations.
To make this possible, it assumes very little about a particular system, and does not keep state between different message exchanges.
This makes HTTP a stateless protocol. The communication usually takes place over TCP/IP, but any reliable transport can be used. The default port for TCP/IP is 80, but other ports can also be used.
Communication between a host and a client occurs, via a request/response pair. The client initiates an HTTP request message, which is serviced through a HTTP response message in return. We will look at this fundamental message-pair in the next section.
The current version of the protocol is HTTP/1.1, which adds a few extra features to the previous 1.0 version. The most important of these, in my opinion, includes persistent connections, chucked transfer-coding and fine-grained caching headers.
HTTP Actions
URLs reveal the identity of the particular host with which we want to communicate, but the action that should be performed on the host is specified via HTTP verbs. Of course, there are several actions that a client would like the host to perform. HTTP has formalized on a few that capture the essentials that are universally applicable for all kinds of applications.
These request actions are:
- GET: fetch an existing resource. The URL contains all the necessary information the server needs to locate and return the resource.
- POST: create a new resource. POST requests usually carry a payload that specifies the data for the new resource.
- PUT: update an existing resource. The payload may contain the updated data for the resource.
- DELETE: delete an existing resource.
The above four verbs are the most popular, and most tools and frameworks explicitly expose these request verbs. PUT and DELETE are sometimes considered specialized versions of the POST verb, and they may be packaged as POST requests with the payload containing the exact action: create, update or delete.
There are some lesser used verbs that HTTP also supports:
- HEAD: this is similar to GET, but without the message body. It’s used to retrieve the server headers for a particular resource, generally to check if the resource has changed, via time stamps.
- TRACE: used to retrieve the hops that a request takes to round trip from the server. Each intermediate proxy or gateway would inject its IP or DNS name into the Via header field. This can be used for diagnostic purposes.
- OPTIONS: used to retrieve the server capabilities. On the client-side, it can be used to modify the request based on what the server can support.
Status Codes
With URLs and verbs, the client can initiate requests to the server. In return, the server responds with status codes and message payloads. The status code is important and tells the client how to interpret the server response. The HTTP spec defines certain number ranges for specific types of responses:
1xx: Informational Messages
All HTTP/1.1 clients are required to accept the Transfer-Encoding header.
This class of codes was introduced in HTTP/1.1 and is purely provisional. The server can send a Expect: 100-continue message, telling the client to continue sending the remainder of the request, or ignore if it has already sent it. HTTP/1.0 clients are supposed to ignore this header.
2xx: Successful
This tells the client that the request was successfully processed. The most common code is 200 OK. For a GET request, the server sends the resource in the message body. There are other less frequently used codes:
- 202 Accepted: the request was accepted but may not include the resource in the response. This is useful for async processing on the server side. The server may choose to send information for monitoring.
- 204 No Content: there is no message body in the response.
- 205 Reset Content: indicates to the client to reset its document view.
- 206 Partial Content: indicates that the response only contains partial content. Additional headers indicate the exact range and content expiration information.
3xx: Redirection
This requires the client to take additional action. The most common use-case is to jump to a different URL in order to fetch the resource.
- 301 Moved Permanently: the resource is now located at a new URL.
- 303 See Other: the resource is temporarily located at a new URL. The Location response header contains the temporary URL.
- 304 Not Modified: the server has determined that the resource has not changed and the client should use its cached copy. This relies on the fact that the client is sending ETag (Enttity Tag) information that is a hash of the content. The server compares this with its own computed ETag to check for modifications.
4xx: Client Error
These codes are used when the server thinks that the client is at fault, either by requesting an invalid resource or making a bad request. The most popular code in this class is 404 Not Found, which I think everyone will identify with. 404 indicates that the resource is invalid and does not exist on the server. The other codes in this class include:
- 400 Bad Request: the request was malformed.
- 401 Unauthorized: request requires authentication. The client can repeat the request with the Authorization header. If the client already included the Authorization header, then the credentials were wrong.
- 403 Forbidden: server has denied access to the resource.
- 404 indicates that the resource is invalid and does not exist on the server.
- 405 Method Not Allowed: invalid HTTP verb used in the request line, or the server does not support that verb.
- 409 Conflict: the server could not complete the request because the client is trying to modify a resource that is newer than the client’s time-stamp. Conflicts arise mostly for PUT requests during collaborative edits on a resource.
5xx: Server Error
This class of codes are used to indicate a server failure while processing the request. The most commonly used error code is 500 Internal Server Error. The others in this class are:
- 501 Not Implemented: the server does not yet support the requested functionality.
- 503 Service Unavailable: this could happen if an internal system on the server has failed or the server is overloaded. Typically, the server won’t even respond and the request will timeout.
Request and Response Message Formats
Let’s now look at the content of these messages. The HTTP specification states that a request or response message has the following generic structure:
message = <start-line>
*(<message-header>)
[<message-body>]
<start-line> = Request-Line | Status-Line
<message-header> = Field-Name ':' Field-Value
It’s mandatory to place a new line between the message headers and the body. The message can contain one or more headers, which are broadly classified into:
- general headers: that are applicable for both request and response messages.
- request specific headers.
- response specific headers.
- entity headers.
The message body may contain the complete entity data, or it may be piecemeal if the chunked encoding (Transfer-Encoding: chunked) is used. All HTTP/1.1 clients are required to accept the Transfer-Encoding header.
General Headers
There are a few headers (general headers) that are shared by both request and response messages:
general-header = Cache-Control
| Connection
| Date
| Pragma
| Trailer
| Transfer-Encoding
| Upgrade
| Via
| Warning
Entity Headers
Request and Response messages may also include entity headers to provide meta-information about the content (aka Message Body or Entity). These headers include:
entity-header = Allow
| Content-Encoding
| Content-Language
| Content-Length
| Content-Location
| Content-MD5
| Content-Range
| Content-Type
| Expires
| Last-Modified
Request Headers
Request Format
The request message has the same general structure as above, except for the request line which looks like this:
Request-Line = Method SP URI SP HTTP-Version CRLF
Method = "OPTIONS"
| "HEAD"
| "GET"
| "POST"
| "PUT"
| "DELETE"
| "TRACE"
SP is the space separator between the tokens. HTTP-Version is specified as “HTTP/1.1” and then followed by a new line. Thus, a typical request message might look like this:
GET /2014/07/http-protocol/ HTTP/1.1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding: gzip,deflate,sdch
Accept-Language: zh,en;q=0.8,zh-CN;q=0.6
Connection: keep-alive
Cache-Control: no-cache
Pragma: no-cache
Host: www.infinitescript.com
Referer: http://www.infinitescript.com/blog/
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/36.0.1985.125 Chrome/36.0.1985.125 Safari/537.36
Note the request line followed by many request headers. The Host header is mandatory for HTTP/1.1 clients. GET requests do not have a message body, but POST requests can contain the post data in the body.
The request headers act as modifiers of the request message. The complete list of known request headers is not too long and is provided below. Unknown headers are treated as entity-header fields.
request-header = Accept
| Accept-Charset
| Accept-Encoding
| Accept-Language
| Authorization
| Expect
| From
| Host
| If-Match
| If-Modified-Since
| If-None-Match
| If-Range
| If-Unmodified-Since
| Max-Forwards
| Proxy-Authorization
| Range
| Referer
| TE
| User-Agent
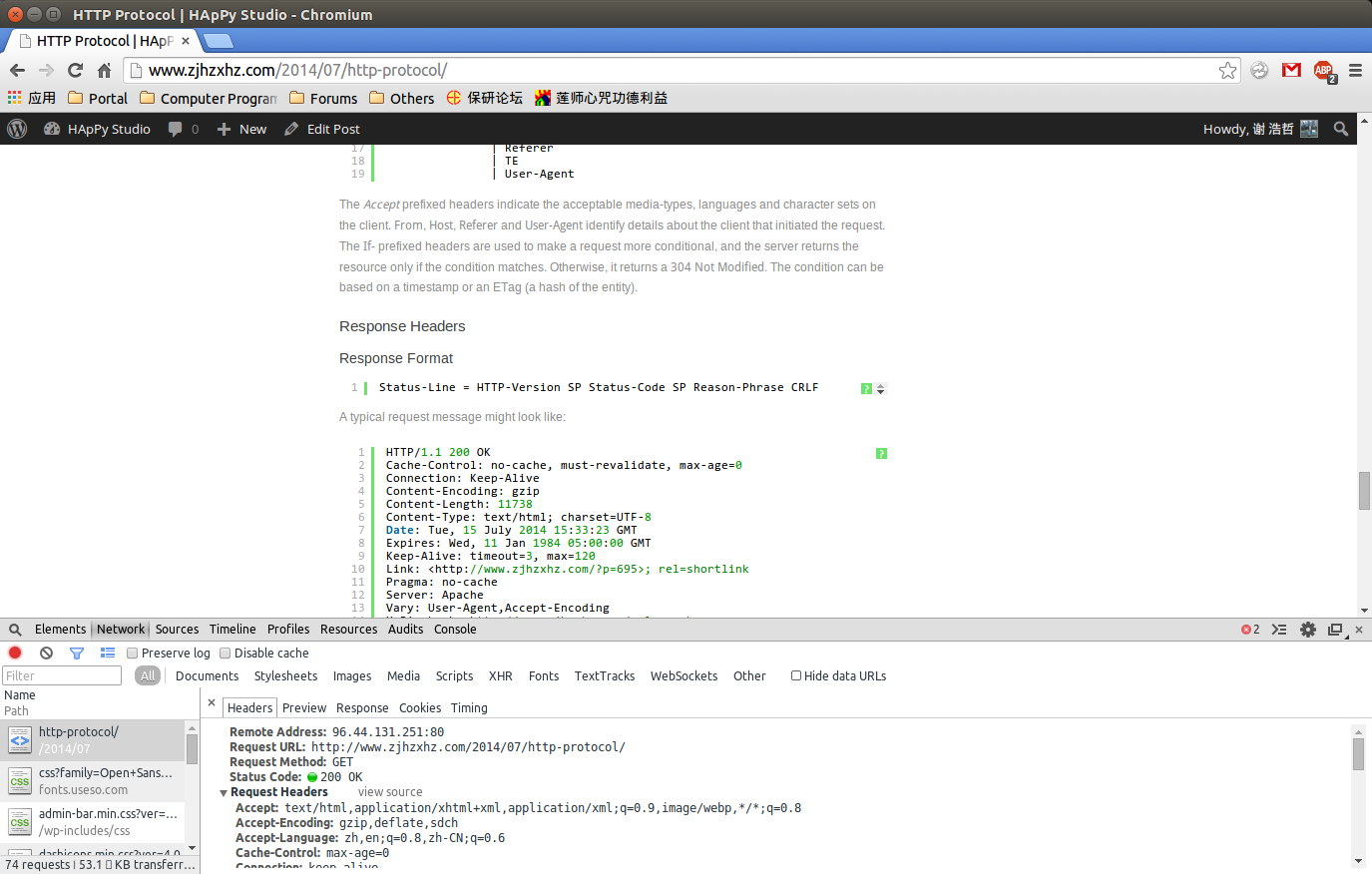
The Accept prefixed headers indicate the acceptable media types, languages, and character sets for the client. From, Host, Referer and User-Agent identify details about the client that initiated the request. The If- prefixed headers are used to make a request more conditional, and the server returns the resource only if the condition matches. Otherwise, it returns a 304 Not Modified. The condition can be based on a timestamp or an ETag (a hash of the entity).
Response Headers
Response Format
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
A typical request message might look like this:
HTTP/1.1 200 OK
Cache-Control: no-cache, must-revalidate, max-age=0
Connection: Keep-Alive
Content-Encoding: gzip
Content-Length: 11738
Content-Type: text/html; charset=UTF-8
Date: Tue, 15 July 2014 15:33:23 GMT
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Keep-Alive: timeout=3, max=120
Link: &lt;http://www.infinitescript.com/?p=53&gt;; rel=shortlink
Pragma: no-cache
Server: Apache
Vary: User-Agent,Accept-Encoding
X-Pingback: http://www.infinitescript.com/xmlrpc.php
X-Powered-By: PHP/5.4.28
The response headers are also fairly limited, and the full set is given below:
response-header = Accept-Ranges
| Age
| ETag
| Location
| Proxy-Authenticate
| Retry-After
| Server
| Vary
| WWW-Authenticate
Ageis the time in seconds since the message was generated on the server.ETagis the MD5 hash of the entity and is used to check for modifications.Locationis used when sending a redirection and contains the new URL.Serveridentifies the server generating the message.
It’s been a lot of theory up to this point, so I won’t blame you for your drowsy eyes.
Tools to View HTTP Traffic
There are a number of tools available to monitor HTTP communication. Here, we list some of the more popular tools.
Firebug
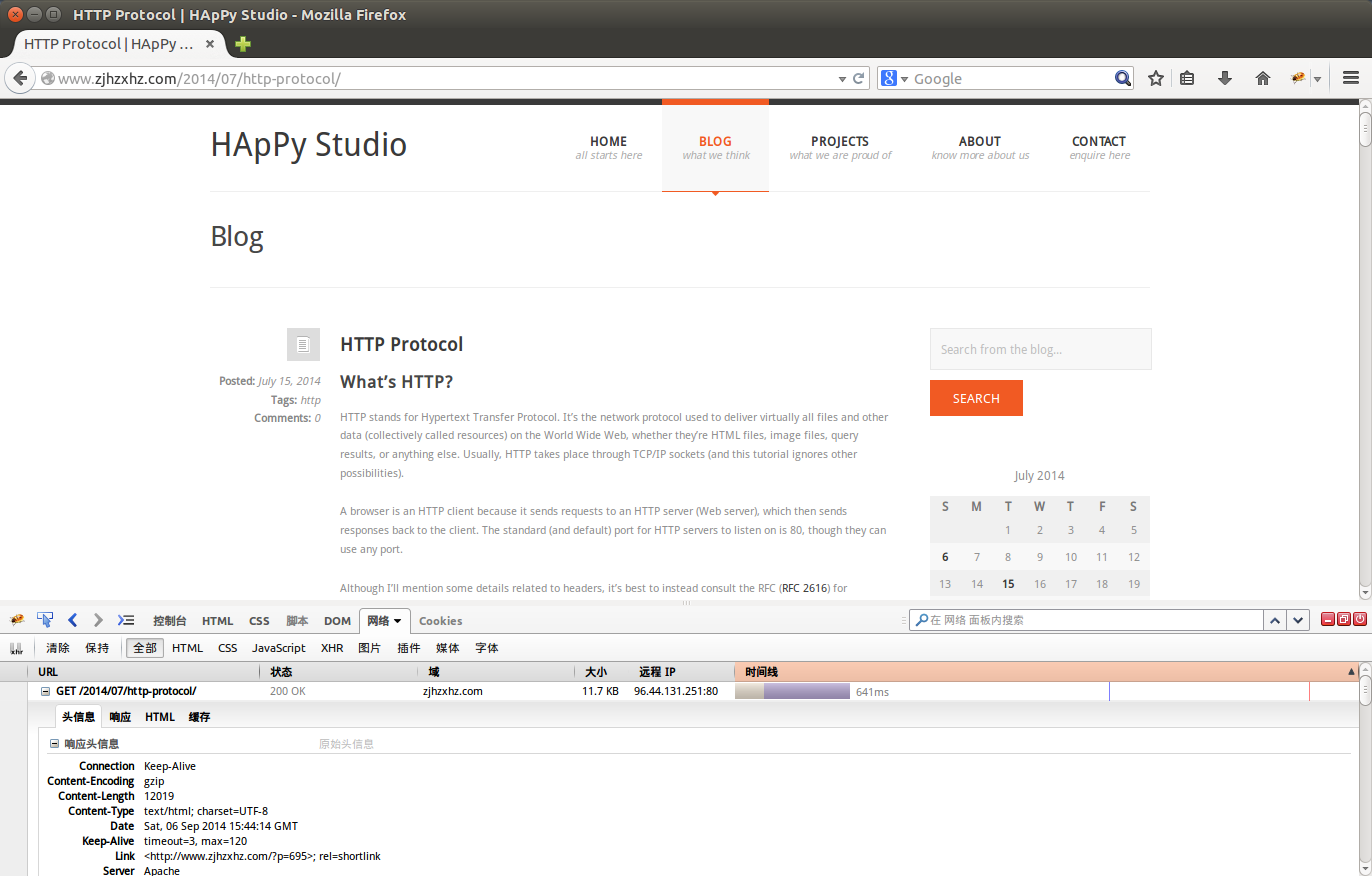
Chrome/Webkit inspector
Cache in Browsers
The most common reason for this is that the page is in your web browser cache. The browser cache is a tool in all web browsers to help pages load more quickly. The first time you load a web page, it is loaded straight from the web server. Then, the browser saves a copy of the page and all the images in a file on your machine. The next time you go to that page, your browser opens the page from your hard drive rather than the server.
Sometimes, the cache will affect the web page displayed. At this time, you can clear the cache in browsers by pressing Ctrl + F5. After you press, there will be two more fields in the HTTP request header: Pragma: no-cache and Cache-Control: no-cache.
Cache-Control/Pragma
This field is a command to control the cache in browsers and proxy servers. Here’s the value of the fields:
- Public: All content will be cached.
- Private: Content will be cached in the primary cache.
- no-cache: All content won’t be cached.
- no-store: All content won’t be cached in Internet Temporary Files.
- must-revalidation/proxy-revalidation: If the cache becomes invalid, it must be revalidated in servers or proxies.
- max-age=xxx: Cache will become invalid in xxx seconds. It has higher priority than Last-Modified.
Cache-Control can be supported in most browsers. It has higher priority, which means the field will cover other fields like Expires.
Pragma is similar to Cache-Control, it tells the servers that do not use cache.
Expires
The common format of Expires is Expires: Tue, 15 Tue 2014 15:23:33 GMT. When this time is exceeded, the cache will become invalid.
If the cache is invalid, the browsers can not use this cache. They must send requests to the servers.
Last-Modified/Etag
The field Last-Modified is used in the server to indicate when the resource was modified recently. For static resources, it will contain this field automatically. For dynamic resources, such as Servlet, you can get this using getLastModified() method.
Usually, the response headers will contain Last-Modified field, telling the browser when the resources were modified, such as Last-Modified: Tue, 15 Tue 2014 15:23:33 GMT. When the browsers get this resource again, the request headers will contain If-Modified-Since: Tue, 15 Tue 2014 15:23:33 GMT. If the resource is not modified since then, the server will return an HTTP response with a 304 status code with an empty response body(no data will be transferred).
ETag is used in servers to allocate a unique identified number for every page. This identified number is used for browsers to tell whether the web page is the latest. But it will take up a lot of resources.
The Disqus comment system is loading ...
If the message does not appear, please check your Disqus configuration.